I’m going to discuss my code to calculate Hypergeometric confidence limits and sample size in Python. In this post I discussed sample sizes for various statistical methods.
Lets first discuss the approach for confidence intervals. Assume we want to calculate a 95% two tailed confidence interval (CI) for a sample size of 284 and sample errors of 3. In all of my example calculations I assume a very large population of 9,999,999. We first need to identify the lower and upper fractiles of the distribution. Alpha = 1 – Confidence Level or 1 – .95 = .05. Since we want a two-tailed interval, lower fractile is 1 – .05/2 = .975 and upper fractile is .05/2 = .025.
In order to identify the confidence interval, we need to identify the number of errors in the population where the cumulative distribution function (CDF) is >= .975 for the lower CI and <= .025 for the upper CI. I utilize the hypergeom.cdf function in the scipy stats Python package in order to calculate the hypergeometric CDF. With a very large population, this could be a pretty computational intensive loop. I wrote an algorithm that skip loops through estimated errors until it meets the loop condition described above. In addition, I utilize the Wilson Score Interval calculation as an estimated starting point.
In the CI function, I return the final result as well as all loop results in dictionaries. This allows me to plot the loop results. For plotting purposes, I’m currently more comfortable with ggplot in R. I exported the results to a csv and then loaded in R to create some plots. In the plot below, this shows that the first population error occurrence where the CDF is >= .975 is 38,506 for the lower confidence interval. The first population error occurrence where the CDF is <= .025 is 305,584.
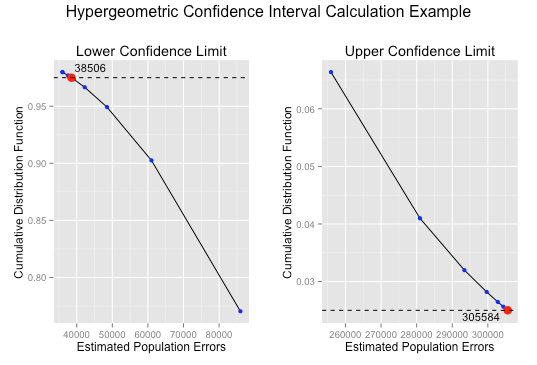
As a result, we calculate the lower confidence limit 38,506 / 9,999,999 = .003850 or .3850%. The upper confidence limit 305,584 / 9,999,999 = .030558403 or 3.0558%. Going back to our original data, sample error rate is 3 / 284 = .01056338 or 1.0563%. We can say our 95% confidence interval for this sample result is between .3850% and 3.0558%. To assess the efficiency of my CI algorithm, it took 24 and 25 iterations for the lower and upper confidence interval calculations respectively. Not bad with such a large population size.
We can also calculate the exact precision we achieved by the maximum of the absolute value difference between the confidence limits and sample error rate. In this scenario, precision exact is .019995023 or 2.0%. Is this a coincidence? Lets take a look with a sample size calculation.
Assume we want to calculate the required sample size for a population with an expected error rate 1% and our desired level of precision of 2%. Lets use the same assumptions we used in the confidence interval calculation for confidence level, two-tailed and population size.
The approach is very similar to the confidence interval calculation. We need to identify the minimum sample size with an approximate sample error rate of 1% (with rounding this can fluctuate some) for that sample size that achieves our desired level of precision. In my research, I found it is possible to land on a sample size that achieves the desired result but then the next loop += 1 it goes back slightly above our desired level of precision. To account for this, I continue the true condition loop until we have 10 consecutive true conditions then I exit the loop.
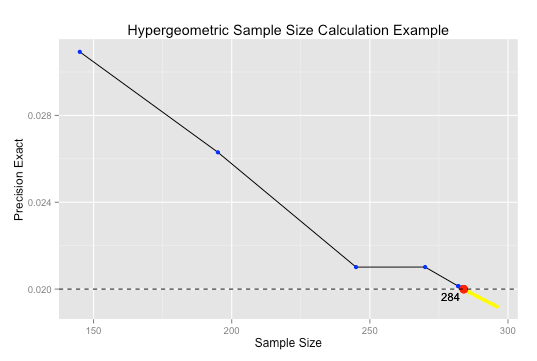
In the SS function, I return the final result as well as all loop results in dictionaries. This allows me to plot the loop results. In the plot below, this shows the minimum sample size of 284. The blue points are false loop conditions and the yellow points are the true loop conditions but beyond our desired result.
My next project is to create a web app in flask using my Python code. The source files for my Python Hypergeometric Distribution confidence limits and sample size calculations can be found here.