In this post I will discuss a common question I’m asked regarding statistical sampling and the use of the normal approximation method to calculate sample sizes. The most conventional and easiest approach to use to calculate sample sizes is the normal distribution. However, I’m going to look more closely using a specific example to see if it also provides sufficient accuracy for the estimate on the population parameter. The example will apply primarily for sampling in a Quality Control or Compliance Testing environment to estimate the number of bad records such as a mortgage or credit card in the population of interest.
The sample size calculation is a two sided confidence interval with z = 1.96 for 95% confidence level. Population size is denoted by N and p is the population parameter. The sampling error is denoted by B and commonly referred to as precision when calculating sample sizes. The expression denoted by n for the normal distribution for a finite population is:
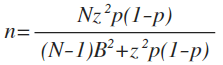
One issue is p is not known. What would be the purpose of selecting a sample if we already know what the population bad rate is? The number of bad records in the sample is denoted by X and we can estimate p by X / n or utilize a worst case estimate. For this example, I will utilize the following:
N = 1000
p = .05
B = .05
Plugging in the values into the expression above we arrive at a sample size of 73.
Another issue is that the underlying probability distribution is in fact not normal. The binomial distribution is a discrete probability distribution that represents the behavior of X when the following conditions are true:
1. Sample size is fixed
2. Each sample selection is independent
3. There is only two possible outcomes
4. The probability of a bad outcome is the same for each record
Our sample size is fixed and there are only two possible outcomes (a good or bad record) but each selection is not independent and the probability of a bad outcome is NOT the same for each selection since the sample was selected without replacement in the population. Typically in these situations the same record would not be examined more than once in the sample so if it is selected it does not have the chance of being selected again.
The correct distribution with these characteristics is in fact the hypergeometric distribution. In certain circumstances the normal distribution can be used to approximate the binomial distribution. The general rule is the normal distribution to approximate the binomial distribution can be used whenever np and n(1 – p) is >= 5. In addition, the binomial can be used as an approximation for the hypergeometric if the population is much larger than the sample size. In this post, I will only discuss the normal approximation to the binomial.
Let’s first determine if this situation is good to use the normal approximation to the binomial. np = 73 * .05 = 3.65 and n(1 – p) = 73 * .95 = 69.35. Since np is < 5, the normal approximation to the binomial may not be sufficiently accurate. Assume we did select the sample of 73 records and upon examination we found 3 bad items. Let’s now construct confidence intervals around the sample proportion of 3 / 73 = .0411. The expression used for a normal distribution confidence interval is:
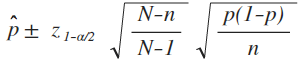
Plugging in the values into this expression we get a lower confidence limit of -.00277, upper confidence limit of .08496 and sampling error of .04387. Since our desired level of sampling error was .05 this gives the appearance that the sample size is sufficient but is it really?
There are several methods available to calculate confidence intervals for the binomial. Built-in functions in Excel for the F distribution and Beta distribution can be used as an estimate. I found a nice website from a Professor at Cal State University Fullerton that utilizes the Clopper-Pearson method. Click here to open that Binomial Probability Confidence Interval Calculator. The expression utilized for the Wilson Score Interval is:

The table below summarizes the confidence interval calculations for each and how they compare to the normal approximation method. The F and Beta Distributions are exactly the same as the Clopper-Pearson method. The Wilson Score Interval has a similar upper confidence limit and sampling error but the lower confidence limit is higher resulting in a tighter confidence interval compared to the other methods.

In this example, utilizing the actual binomial confidence intervals demonstrates that a sample size of 73 based on the normal approximation method is in fact not sufficient to achieve a maximum sampling error of .05 with 95% confidence level when the sampling proportion is .0411. The actual sampling error is closer to .07434.
As I stated earlier, the correct underlying distribution is hypergeometric so we will discuss that in another post to further analyze this topic.
References
Binomial Distribution
Binomial proportion confidence interval
Normal Approximation to the Binomial Distribution